
Oracle 從 8.1.6 開始提供分析函數專門用於解決複雜報表統計需求的功能強大的函數。它可以在資料中進行分組然後 計算基於組的某種統計值,並且每一組的每一行都可以返回一個統計值。
分析函數為我們實現各種需求報表帶來了極高的便利性,如果能靈活使用,將可大幅提高工作效率。今天主要簡單描 述 Rank ( ) over ( )、Dense_Rank ( ) over ( ) 兩函數的用法。
Rank 的基本語法
RANK ( ) Over ( [query_partition_clause] order_by_clause )
Rank ( ):根據 ORDER BY 子句中運算式的值,從查詢返回的每一行,計算它們與其它行的相對位置。組內的資料按 ORDER BY 子句排序,然後給每一行賦一個號,從而形成一個序列。該序列從 1 開始,往後累加。每次 ORDER BY 運算式的值發生變化時,該序列也隨之增加。有同樣值的行得到同樣的數字序號(認為 null 時相等的)。
使用 Rank ( ) 函數時,如果兩行得到同樣的排序,則序數將隨後跳躍。若兩行序數為 1,則沒有序數 2,序列將給組 中的下一行分配值 3。
部門員工離職人數排序
select a.adept_no, a.num_per, rank () over ( partition by a.dept_no order by > a.num_per ) rk from hr_per_out a;
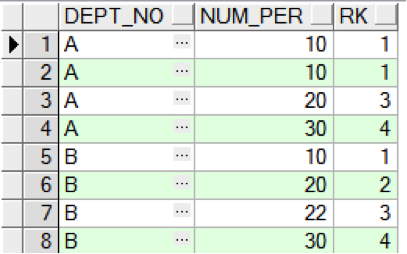
A 部門內有兩排序為 1,下一行的排序就跳為 3 了。
Dense_rank ( )
Dense_Rank ( ) 與 Rank ( ) 用法相當,但是有一個區別:Dense_Rank ( ) 在處理相同的等級時,等級的數值不會跳 過。Rank ( ) 則跳過。
select a.dept_no, a.num_per, dense_rank() over ( partition by a.dept_no order by a.numper ) rk from hr_per_out a;
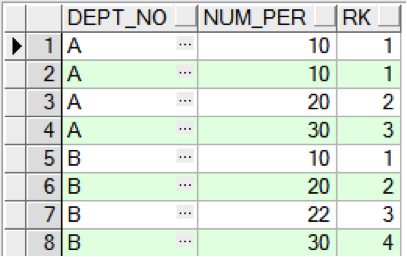
通過結果看到,使用 Dense_Rank ( ) 函數排序後,A 部門下有兩個相同的排序 1,但是之後的排名還是 2,這就是 Dense_Rank ( ) 跟 Rank ( ) 函數不同之處。
總結起來說,Rank ( ) 是跳躍排序,如上,A 部門有兩個第一名,那麼接下來就是第三名字。Dense_Rank ( ) 是連續 排序,比如有兩個第一名時仍然跟著第二名。
以上僅是對兩排序函數用法的一個簡單總結,還可以使用 Last_Value ( ) over ( ),First_Value ( ) over ( ) 來結合 Dense_Rank ( ) over ( )使用,如取出排序後的最後一筆資料和第一筆資料……等。Oracle 的分析函數還有很多種,可以靈活組合使用,實現多種不同的需求。
分析函數的使用,可以從大量的資料中簡明扼要的呈現出使用者所需要的資料。結合資通人資系統 HCP 資料能夠準確提煉出使用者所需要的資訊。